一、编程模型和硬件架构
由于AI应用对巨大算力的极致追求,各种针对AI计算场景的AI芯片架构层出不穷。AI软件栈的复杂性就来自于硬件架构的跨越式发展。而面对这样的复杂度,AI软件编程模型的设计和架构就变得至关重要。
编程模型就是对编程共性的抽象,或许可以从两个层面理解:
- 架构上,是对底层硬件架构和对软件的组织、复用、交互方式的抽象
- 工程上,可以是一个或几个软件中间层所提供的上层应用开发接口。是基于硬件的岩石之上,让上层软件生态得以发展的土壤层
本文基于对Nvidia CUDA和Graphcore Poplar编程模型的调研,希望能谈谈个人对AI芯片的编程模型的一些看法。
二、现有AI芯片的编程模型
1. Nvidia CUDA
编程模型
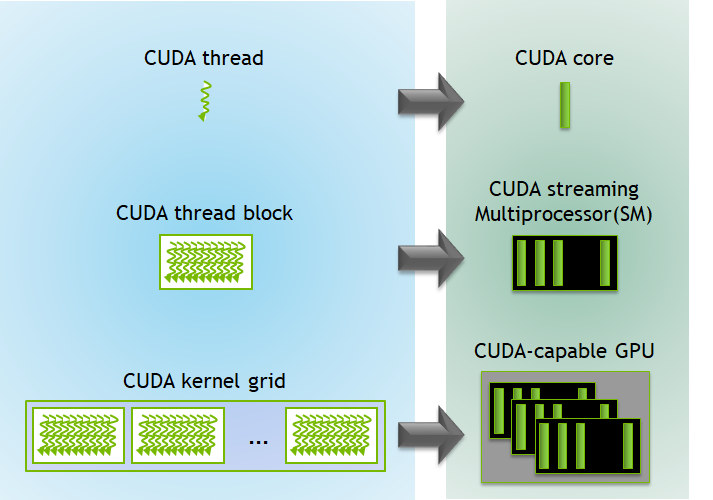
GPU的硬件结构
- 一块GPU由多个SM (Streaming Multiprocessors)组成
- 每个SM中包含多个计算core
与之对应的编程模型
- 采用Host - Device(kernel) 异构编程模型
- 将多核并发抽象为Grid, Block, Thread 三级线程模型
- kernel程序通过控制block和thread数量,可以模拟多维数据的并行计算
- 提供丰富的并发和异步操作的同步支持
- CUDA采用Single Instruction Multiple Thread(SIMT)的方式管理和运行代码
- 每个thread block会被调度到其中一个SM上执行
- 每32个thread组成一个warp,SM以warp为单位进行调度。在一个warp中,所有thread执行同一个指令流。
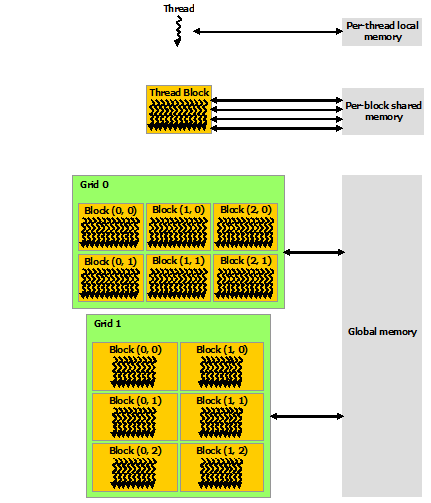
存储管理
GPU采用多层级存储结构,而CUDA接口提供了通过软件细粒度控制储存的能力:
- 本地内存(local memory),为每个线程私有
- 共享内存(Shared Memory),每个block内线程共享
- 全局内存(Global Memory),所有线程共享
常量内存(Constant Memory)和纹理内存(Texture Memory)
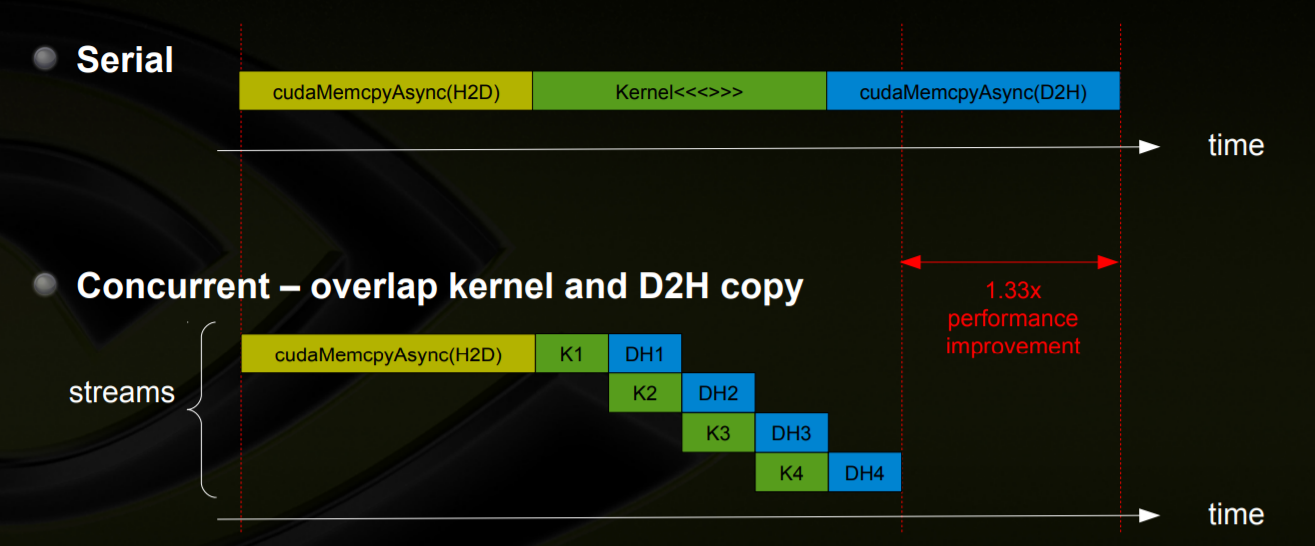
并发和同步
CUDA编程模型提供多层次的并发支持:
- 同步API(如
cudaMemcpy,kernel程序并行,但是host-device间数据拷贝串行) - 异步操作 (Asynchronous Operations) API(如:cudaMemcpyAsync 将数据拷贝和计算并行)
- 基于Stream的异步操作模型
- 一个流内的操作按照FIFO的方式依次执行
- 不同流内的操作可以并发或交替执行
相应的对于不同并发模式,也提供了多种同步方法:
- 对于CUDA线程,除了
__syncthreads()``__syncwarp()等用于同步同一线程块内和同一线程束内的所有线程的粗粒度同步原语。CUDA 9之后还引入了Cooperative Groups,提供更灵活的线程管理方式,可以实现block内,跨block,甚至跨GPU的线程group管理和同步方法。 - 使用同步对象对异步操作进行同步
- 使用Event和Callback机制对Stream进行同步
2. GraphCore Poplar
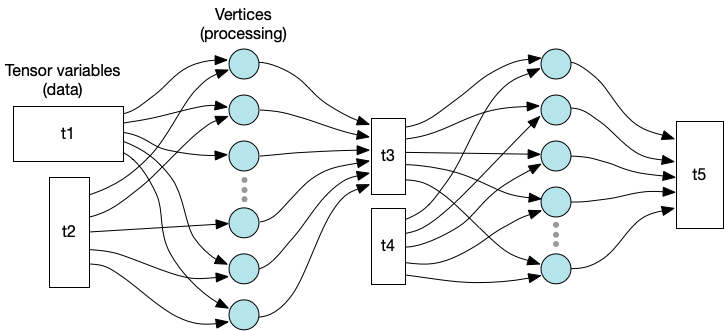
编程模型
- 数据由Tensor variable描述
- 每个计算节点由vertex描述
- vertex的输入输出可以和variable做连接,最后组成一张计算图
存储结构
- 不同于CUDA的多层存储结构,GraphCore IPU 不采用多层级的共享存储模式,而是采用片内SRAM实现大规模的分布式本地存储。
- 提供Data Stream处理Host和Device间数据传输
- 提供Remote buffers用于访问片外存储
并发和同步
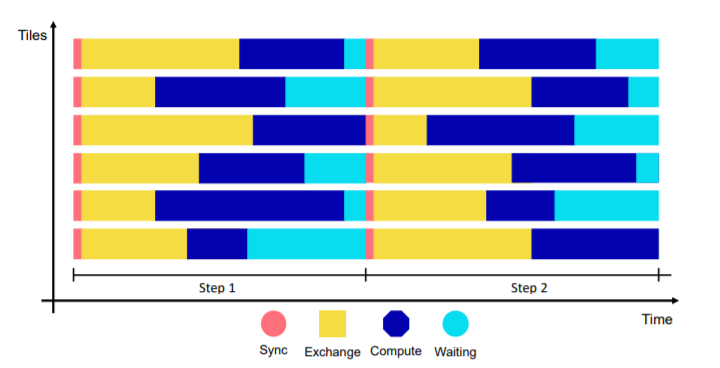
计算图可以被分配到IPU上的不同tile上面执行,每个tile执行一个或多个vertex,数据操作都在tile的本地存储上完成,然后将结果传递给其他tile。
IPU采用了一个称为Bulk Synchronous Parallel (BSP)的运行模式来执行并行操作:
- 本地计算阶段(local compute), 每个tile只对存储本地内存中的数据进行本地计算。
- 全局同步阶段(global synchronization), 等待所有tile计算完成
- 数据交换阶段(data exchange), tile之间进行数据交换
每个tile数据交换结束后,就切换到新的本地计算阶段,重复BSP流程。
三、AI芯片编程模型的思考
1. CUDA和Poplar编程模型的对比
- 通用性:
- CUDA的定位是通用并行计算平台,支持所有CUDA-enabled GPU的在不同场景下的应用。十几年中SIMT的编程模型有效的支持GPU硬件架构的持续演进,适合多领域的通用计算场景。
- Poplar的编程模型则是为了GraphCore IPU特有的硬件架构服务, 图计算的编程模型更适合深度学习的计算模式。
- 并行设计理念的不同:
- CUDA是典型的SIMT模式,依靠计算并行取得性能的提升。在数据搬运或者当thread中代码发生分支时,会因为同步等待造成性能损失,所以提供了steam、Cooperative Groups等方式来提升并发性能。
- 而Poplar则是更接近MIMD(Multiple Instruction, Multiple Data)模式,采用激进的存储模式来减少数据读写的延迟,采用高效的tile间和芯片间通信解决片上存储无法容纳大模型等问题,为了简化通信同步的复杂度又采用了运算和通信串行的BSP模式。
- 易用性不同:
- CUDA API很好的抽象了GPU计算的通用性,但是编程难度很高。当GPU架构为了更好的支持深度学习计算添加了Tensor Core之后,CUDA也引入了WMMA(warp-level matrix multiply and accumulate)API支持矩阵运算,又进一步加剧了CUDA编程的困难度。但是CUDA生态枝繁叶茂,又为各种场景下的软件开发带来了便利,比如很多用户可以通过cuBLAS 和 cuDNN等更上层的计算库使用Tensor Core算力,不需要直接基于CUDA API开发。
- 相对而言Poplar的编程模型比较简单,单一的存储管理和计算通信串行的模式,都极大的简化了编程难度。但是如此特殊的硬件架构以后如何演进不得而知,如果发生较大变化,可能编程模型需要极大调整,使用难度也会增加。
2. 编程模型设计的考量
编程模型和硬件架构是互相促进,又互相制约的关系:
- 编程模型需要准确抽象硬件特点,能够发挥硬件架构特点,释放硬件性能。
- 硬件架构的演进又直接影响编程模型的稳定性和软件的开发难度。对于AI芯片这样专用架构的硬件尤其如此,每次架构的调整都是对软件栈开发的巨大挑战。
结合以上两种芯片编程模式的不同特点,我认为对一个设计良好的编程模型应该满足一下特点:
- 通用性
- 一是功能的完备性,体现在拥有完备的语义,可以覆盖所有应用场景,
- 二是接口的稳定性,体现为可以保证已有上层软件(如算子库)对新硬件的兼容性或者可移植性。
- 高性能
- 发挥硬件设计特点
- 提供必要的细粒度操作支持
- 易用性
- 编程模型贴近应用场景
- 存储、并发、通讯等机制简单
然而同时满足三个特点确实非常难做到,这里面可能要平衡以下冲突:
- 通常通用性意味着复杂的抽象,很可能会造成易用性的下降
- 高性能的设计也通常需要更细粒度的硬件操作,在硬件变化后,很难保证接口的通用性。
- 对某个应用场景更简单的机制,可能无法扩展到其他领域,或者带来性能的损失。
要克服这些冲突,或许可以不追求在所有时间内同时满足三个特点:
- 在产品化初期追求易用性和高性能,借助市场反馈,丰富上层生态,提升通用性
- 在产品化成熟后追求通用性和高性能,利用生态便利性提升易用性,同时建设软件基础设施。
- 在硬件演进过程中,利用成熟的基础设施和技术创新(AI编译器?分布式技术?),快速迭代软件栈,保证通用性和高性能的延续。