如何衡量目标检测算法的优劣
目标检测(object detection)问题相对于一般AI分类问题更加复杂,不仅检测出目标,输出目标的类别,还要定位出目标的位置。分类问题中的简单accuray指标已经不能反映出目标检测问题结果的准确度,而mAP (Mean Average Precision)就是被用来衡量目标检测算法优劣的常用指标。
要理解什么是mAP,需要先澄清什么是Precision(查准率)和Recall(查全率)。
Precision和Recall
定义
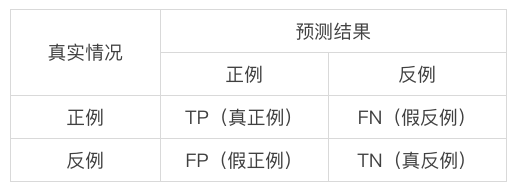
查准率和查全率是在信息检索、Web搜索等应用中经常出现的性能度量指标,在机器学习中,也可以用来度量“预测结果中有多少比例是用户感兴趣的”。对于二分类问题,可将样例根据其真实类别与预测类别的组合划分为:
TP、TN、FP、FN
- TP (True Positive): 真正例。Positive指预测输出为正,True代表预测正确。
- TN (True Negative): 真反例。预测输出为负,而且预测正确。
- FP (False Positive): 假正例。预测输出为正,但是预测错误。
- FN (False Negative): 假反例。预测输出为负,但是预测错误。
Precision
Precision(查准率): 所有预测为正例的结果中,预测正确的比率。

Recall
Recall (查全率):所有正例中被正确预测的比率。

如何计算
目标检测问题中,算法通常输出一个预测框(bounding box)来标识检出目标的位置,要衡量这个预测框与目标的实际位置(ground truth)的准确度,可以使用IoU指标。
交并比IoU(Intersection over union)
交并比IoU衡量的是两个区域的重叠程度,是两个区域重叠部分面积占二者总面积(重叠部分只计算一次)的比例。
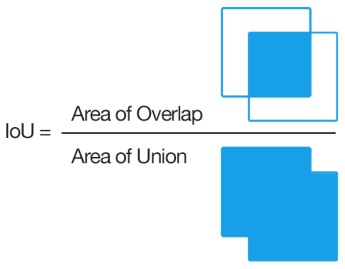
目标检测中IoU就是预测框与实际框的交集除以并集。
我们可以设置一个阈值(threshold),通常是0.5,预测结果可以分为:
- 如果IoU >= 0.5
- 如果预测类别也正确,认为是一个好的预测,分类为TP
- 如果预测类别错误,认为是一个坏的预测,分类为FP
- 如果IoU < 0.5, 认为是一个坏的预测,分类为FP
- 如果一个目标出现在图像中,但是算法未检出,分类为FN
- TN(图像上所有不包含实际框和检测框的部分)通常计算中用不到。
AP和mAP
P-R曲线
查全率和查准率通常是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
我们如果把所有预测结果对样例进行排序,排在前面的是“最可能”的正例样本,以查准率为纵轴、查全率为横轴作图,得到一条”P-R曲线”。
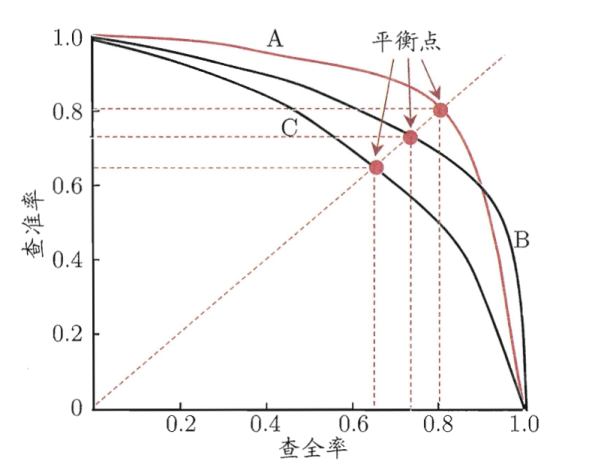
P-R曲线直观的显示出一个算法在样本总体上的查全率、查准率情况。如果一个算法的P-R曲线被另一个算法的曲线完全包住,则可断言后者优于前者。但是实际中,经常不同算法的P-R曲线是互相交叉的,这时就很难直观判断出两者的优劣。这时通常会考察平衡点(BEP)、F1度量、AP等指标。
AP
AP(average precision 平均精度):AP是计算单类别的模型平均准确度。对于目标检测任务,每一个类都可以计算出其Precision和Recall,每个类都可以得到一条P-R曲线,曲线下的面积就是AP的值。如果一个算法的AP值较大,也就是P-R曲线下的面积比较大,可以认为此算法查准率和查全率整体上相对

mAP
mAP(mean of Average Precision) : 对所有类别的AP值求平均值。
Pascal VOC(VOC2007 & VOC2012)是评测目标检测算法的常用数据集,VOC数据集使用一个固定的IoU阈值0.5来计算AP值。 但是在2014年之后,MS-COCO(Microsoft Common Objects)数据集逐渐兴起。 在COCO数据集中,更关注预测框位置的准确性,AP值是针对多个IoU阈值的AP平均值,具体的就是在0.5 和0.95之间取10个IoU阈值(0.5、0.55、0.6 ….. 0.9、0.95)。所以VOC数据集中mAP通常标记为mAP @ IoU=0.5, mAP@0.5 或者 mAP_50,在COCO 数据集中册标记为 mAP @ IoU=0.5:0.05:0.95, mAP @ IoU=0.5:0.95 或者 mAP@[0.5:0.95].
参考:
https://blog.csdn.net/weixin_44791964/article/details/102414522
[https://www.jianshu.com/p/fecc98e448d9](